The One Problem With My Racks & The NDS-4600-JD-05
6 Jan 2021

My zero-U PDUs get covered up as my rack isn't super super deep.

My zero-U PDUs get covered up as my rack isn't super super deep.
One issue I've recently run into with a failed SATA drive in one of my NDS-4600 units is that Linux frequently tries to recover the drive by resetting the bus. This takes out a few other disks in the group with it. The resulting IO timeouts cause problems for my Ceph OSDs using those disks.
It should be noted that only some types of disk failures cause this. The host bus resets only are done by the Linux kernel in some cases (I think) and I suspect the cause of the other disks errors is said disk.
I've turned off the VA-Sterling room for now as I've got my node defaulting to the Virginia room with a few other nodes in the state.

The Sterling, VA, USA repeater and WIRES-X node is now up and operational.
It is a full duplex WIRES-X node, C4FM Repeater, and FM Repeater in FM19ha run by KG4TIH.
Ceph has two forms of scrubbing that it runs periodically: Scrub and Deep Scrub
A Scrub is basically as fsck for replicated objects. It ensures that each object's replicas are all the latest version and exist.
A Deep Scrub is a full checksum validation of all data.
My Ceph cluster at home isn't designed for performance. It's not designed to maximum availability. It's designed for a low cost per TiB while still maintaining usability and decent disk-level redundancy. Here is some recent tuning to help with performance and corruption prevention....
Sterling, Va now has a Wires-X node (100% digital with full control) on 439.800MHz.
Note: If/when coordinated frequencies come in and the associated repeater is up, the frequencies will change.
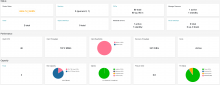
Previously I posted about the used 60-bay DAS units I recently acquired and racked. Since then I've figured out the basics of using them and have them up and working.
I was getting this from podman on a CentOS 8 box:
"error from slirp4netns while setting up port redirection: map[desc:bad request: add_hostfwd: slirp_add_hostfwd failed]"
It was fixed by killing off all podman and /usr/bin/conmon processes as the user that I was running the commands as. Note: Don't do that as root using killall unless you limit to only your user.
The underlying error may have been running out of FD.
